This article on Tranfer Leaning is a continuation of previously published articles on Artificial Intelligence (AI) on this blog. For more information: “From Big Data to Machine Learning to Deep Learning – The progress of AI” and “The Data-centric World of Artificial Intelligence (AI)”.
Introduction to Transfer Learning
Any article on Artificial Intelligence (AI) will point out that trying to address an AI problem requires large amounts of data to deliver meaningful results. To train the data into a usable AI model, a massive amount of compute capacity is needed. On top of that, it is challenging to find resources from a limited pool of people with skills that are in high demand. Putting all the pieces together is costly and time-consuming.
What if there isn’t a lot of data available for the problem we are trying to address? Do we have to re-invent the wheel each time we look at a challenge? Can we learn from past AI solutions and re-apply that knowledge to solve new AI problems? The ability to learn from previous solutions is precisely what “Transfer Learning” is all about.
The concept is not new. Teachers transfer knowledge to students. Students apply that knowledge to solve tasks daily. When we address tasks that are similar to our knowledge base, we will yield better results. Less related tasks will require additional expertise before we can move on and complete the tasks. Eventually, all that added knowledge will allow us to tackle more complex tasks. Transfer learning is the continuous process of transferring knowledge to improve problem-solving capabilities over time.
For example, consider all the knowledge somebody acquires from learning to ride a bicycle. When the same individual wants to learn to ride a motorcycle, the bicycle experience makes the transition much smoother. Without the experience, it would take more time to be as proficient with the motorcycle. Likewise, when learning to drive a car, the combined knowledge from riding the bicycle and the motorcycle accelerates our ability to become a skillful driver.
Traditional vs. Transfer Learning
In this blog, we refer to Traditional Learning as types of Machine Learning (ML) such as Supervised, Unsupervised, and Reinforcement Learning. For more information and definitions, please see my previously published articles on AI.
Let’s have a look at the differences between Traditional Learning and Transfer Learning.
In Traditional Learning, we train a new model with given datasets and task or domain. The trained model is considered isolated in the sense that it is trained with no outside knowledge. All the knowledge that resides in the model comes from extracting knowledge from the given datasets.
Transfer Learning uses accumulated knowledge from pre-trained models and transfers that knowledge to a new model to solve more complex problems. The new model is an extended version of the original model.
Example
The best way to demonstrate the concept is to use an example. The goal of the project is to build a model that detects a wake-up or trigger word. The same way Amazon Echo gets activated by the word “Alexa”. However, we are not going to train a model from scratch but instead transfer knowledge from the existing Speech Recognition model to our new model. The net result is a new model for trigger word detection based on a pre-trained model.
Traditional Model
Our starting point is a Speech Recognition model pre-trained with large datasets consisting of audio files. For any given audio input, the model will attempt to recognize words and return them as output. Figure 1 shows a Speech Recognition network with seven (7) layers. Data travels through the network from the left (input) to the right (output).
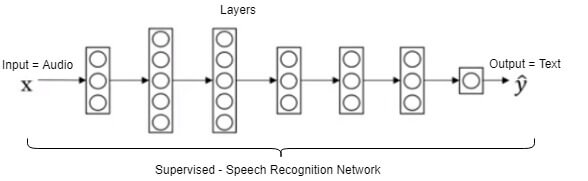
| Figure 1 – Traditional Learning Network |
The pre-trained Speech Recognition model has accumulated knowledge during its training phase, and it is that knowledge we want to transfer to a new model. The new model will consist of the pre-trained Speech Recognition network followed by a network that enables trigger word detection.
Let’s assume that for the trigger word detection part we are going to need a small network of three (3) layers. As input, it will accept audio and return a trigger word if one was detected (output). Additionally, we have at our disposal a small dataset that will help with the training of the trigger word detection.
New Transfer Model
In Figure 2 on the left, we have (1) the pre-trained Speech Recognition network. We won’t be needing the (2) output layer of that network. Next (4) we attach/add the (3) network for trigger word detection to the pre-trained model. The combination of both networks results in a nine (9) layer network as pictured.
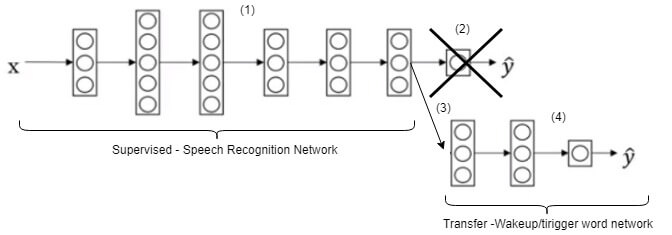
| Figure 2 – Transfer Learning Network |
We feed the dataset for trigger word detection to the input of the new network. The retained knowledge in the pre-trained model is transferred to our new model as it traverses the layers. In transfer learning, knowledge (training parameters) can be leveraged from previously trained models for training of newer models. Finally, the trigger work detection network is trained with the help of the acquired knowledge.
The result is a model that takes audio as input and is capable of detecting a trigger word.
Performance
The goal of Transfer Learning is to improve the performance of a model by transferring knowledge. How can we measure this performance?
Figure 3 compares the training performance of transfer training against training without transfer, i.e. traditional learning.
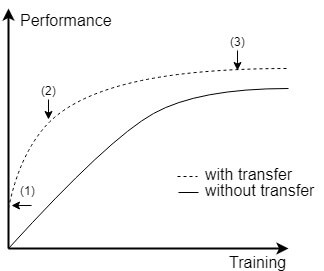
- First off, the graph shows that there is already a potential performance gain (1) just by using the transferred knowledge.
- Secondly, we can observe that (2) the learning curve is steeper with transfer learning which means we are learning at a faster pace.
- Finally, over time, (3) a higher performance can be achieved with transfer learning.
| Figure 3 – Transfer Learning Performance |
The use of Transfer Learning
Transfer Learning relies on carrying over knowledge acquired from other model training sessions to increase performance. In a way, it is extending the usefulness of existing algorithms and models. It can be a time saver and beats training a model from the ground up. Less processing time results in a reduced need for computing resources and overall lower cost. Additionally, it doesn’t require large amounts of data to get started. Furthermore, it reduces the dependency on specialized skills and resources.
A good use case for Transfer Learning is when access to data is problematic or lacking. A model trained with large amounts of similar data can act as a good platform. The knowledge from that base model can be transferred to the new model and compensates for the lack of data.
The knowledge transfer allows getting started, obtain results quickly with increased performance. And as more data becomes available, the model can be further optimized.
However, using Transfer Learning is not a guarantee for success. There needs to be a close relationship between the pre-trained and the transfer model. For example, it makes sense to use a pre-trained model of images to train a transfer model that detects cars in images. The relationship, in this case, is images. When the association is weak, the knowledge transfer might contribute negatively. Instead of improving performance it makes it worse. It is called Negative Transfer Learning and not the desired outcome.
Economical Value of Transfer Learning
Andrew Ng is the co-founder of Coursera and adjunct-professor at Stanford University and is a well-known AI expert. In his NIPS 2016 tutorial called “Nuts and bolts of building AI applications using Deep Learning”, he described Transfer Learning as the next driver of ML’s commercial success.
In Figure 4, taken from his tutorial, Ng describes the various learning methods and their commercial potential. It shows that Supervised Learning was the method leader with the highest commercial value in 2016. While Transfer Learning seems to trail behind, it shows an increase in business value post-2016.
Transfer Learning lowers the barrier to engage in AI as well as accelerates market penetration.
Enterprises that are already engaged in AI are looking at ways to address new challenges. Transfer Learning allows them to get faster results and increased performance. Time to market is a crucial competitive advantage. Another aspect is the ability to diversify by experimenting with pre-trained similar models.
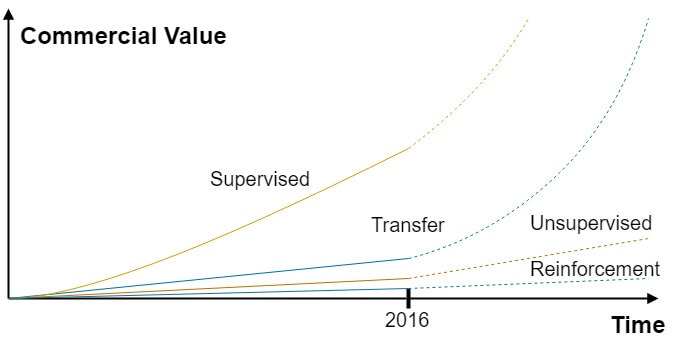
"Transfer Learning is the next driver of ML’s commercial success."
-Andrew Ng, 2016
| Figure 4 – Transfer Learning – Commercial Value |
What’s next?
Although outside of the scope of this blog, it is worth mentioning “Multi-Task Learning” (MTL).
In “Transfer Learning”, the knowledge flows in just one direction. Namely from the source task to the target task. In “Multi-Task Learning,” we have multiple tasks learning from each other at the same time. This type of learning is more complicated as data flows between all the tasks and in all directions. However, it is capable of handling more complex situations.
Figure 5 visually depicts the possible data flows for the two types.
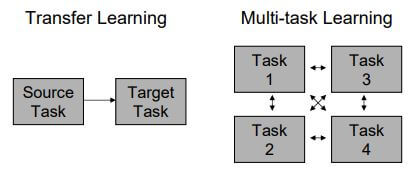
| Figure 5 – Transfer vs Multi-task Learning |
A use case could be e-mail filtering (“spam”) as MTL provides the ability to run distinct but related classifications tasks across multiple users to identify spam.
Summary
Transfer Learning uses accumulated knowledge from pre-trained models and transfers that knowledge to a new model. The approach opens the door to solve more complex problems. The goal is to improve performance and reduce the overall time to train a new model.
Transfer Learning can be very useful in cases where there is not a lot of data available. Transferring knowledge from a model trained with the help of large datasets can increase performance significantly. However, it is essential to avoid negative learning which decreases the performance.
The concept of Transfer Learning has been around for a long time. With a growing pool of readily available pre-trained models, the Transfer Learning method promises to move ML forward.
Transfer Learning is becoming a key driver for ML, and its economic value is snowballing. Enterprises can benefit from quickly extending existing pre-trained models with improved performance. On the other hand, enterprises with little experience can benefit from bootstrapping their ML projects with Transfer Learning.
Transfer Learning is helping to advance ML and AI in general with its ability to retain knowledge and extend existing models.
References:
- “Transfer Learning” by Lisa Torrey & Jude Shavlik
- “Transfer Learning (C3W2L07)” by Andrew Ng
- NIPS 2016 tutorial: “Nuts and bolts of building AI applications using Deep Learning” by Andrew Ng