Introduction to Natural Language Processing (NLP)
Of all the data that is available to us, only 20% [1] of it is in a structured or in a pre-defined format. The remaining 80% of the data is in an unstructured form, with most of it being textual data. The lack of structure increases complexity and makes it challenging to process data, find patterns, and apply analytics in a meaningful way. Some examples of unstructured data are documents, audio files, images, and videos. Many sources on the Internet, such as social media and news sites, create massive amounts of unstructured data.
Natural Language Processing (NLP) supports Artificial Intelligence (AI) to allow a computer to understand, analyze, manipulate, and generate human language. In other words, NLP is learning how people communicate and teach machines to replicate that behavior. Ultimately the goal is to interact with devices in a more natural, human-like way. Machines can analyze large quantities of language data more consistently and faster than humans.
Like any other AI technology, it has been around since the 1950s. In the early days, NLP was rule-based with many limitations, and it lacked a human touch. For humans, written or conversational speech comes naturally, but it is very complex to a machine to learn and achieve the same level of comprehension. The rise of Machine Learning (ML) reduced the need for rules, but it is Deep Learning (DL) that provided a progressive approach that is closer to human behavior. For more information, see my blog on ML and DL.
Recent advances
The recent advances in NLP are only possible due to the increasing compute capacity (Moore’s Law). NLP is now able to process significant amounts of data (text) in a reasonable timeframe with improved results. Automating the NLP process is critical to thoroughly and efficiently analyze text and speech data. Another major contributor is the recent advances, initiatives, and innovations around Deep Learning (DL) targeting NLP.
Some of the everyday use cases for NLP are:
- Sentimental analysis
- Speech Recognition (SR)
- Chatbots
- Automated Assistants
- Machine Translation
- Text-to-Speech (TTS)
- Automatic Summarization
- Spell Checking
- Keyword searching
- Information Extraction
- Language Classification
- Language Generation
Typically NLP has two distinct phases:
- Natural Language Understanding (NLU):
- In this phase, the idea is to decompose unstructured input and create a structured ontology that a machine can understand. For its decision making, it relies on grammar and context combined with intent. In other words, trying to understand what the user is saying or what the user intended to say.
- Humans are capable of handling mispronunciations, transposed words, and contractions. However, this is a real challenge for machines, and that is what NLU is trying to address.
- Natural Language Generation (NLG):
- The NLG phase starts with the structured ontology (NLU) and generates meaningful phrases and sentences, all of this in a conversational way, while using correct language and grammar in such a way that the interaction seems natural.
Use case – NLP
The automated assistant: use case of NLP.
NLP is a crucial component in the interaction between people and devices. People talk to an assistant such as Amazon Alexa, Apple Siri, Google Voice, with the help of Speech Recognition, Text-To-Speech, and NLP.
The first step is to map your question (audio) to a list of words (text) with the help of a Speech Recognition engine. Then the NLP puts the words into context and tries to understand the meaning behind them. With the correct understanding, NLP can generate a comprehensive response. Finally, the generated sentence (text) is sent to the Text-to-Speech engine to deliver the answer in an audio format.
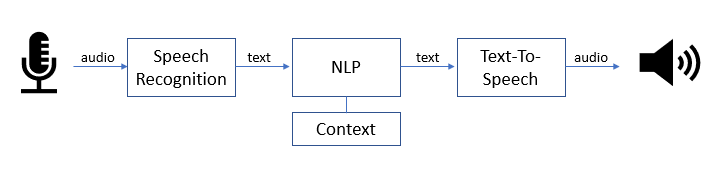
| Figure 1- NLP Use Case – Automated Assistant |
BERT
In recent years, new NLP models have shown significant improvements. We say new, but in reality, the ideas used in those models have been around for a while, but developers weren’t able to implement them successfully.
BERT (Bidirectional Encoder Representations from Transformers) is an open-source NLP model that was released by Google in October 2018[4][5]. It’s a significant milestone for the NLP world as it uses a different approach with many improved results. Until then, the training in most models happened by predicting each word conditioned on the previous word in the sentence. The concept was to walk through a sequence of words from left to right or right to left.
Transformer model (the T in BERT)
The Transformer is a deep machine learning model introduced in 2017. Transformers are designed to handle ordered sequences of data for various tasks such as machine translation and text summarization. The Transformer model allows for a higher level of parallelization compared to RNNs (Reccurent Neural Network) because it doesn’t need to process the beginning of a sentence before it processes the end.
What makes BERT so unique? BERT applies context that relates to all the words in a sentence. It can analyze the words in a sentence by traversing it bi-directionally (see Transformer). In other words, it can deduce the context of a word by looking at the other words in the sentence. The bi-directional aspect is one of the main features that make BERT a powerful training model for NLP. The model learns the context of a word based on all its surroundings. BERT can also be used for tasks such as “question and answering” where the relationship between two sentences is required (aka Next Sentence Prediction, NSP).
Some of the benefits of BERT:
- The improved understanding of word semantics combined with context has proven that BERT is more effective than previous training models.
- BERT can be successfully used to train vast amounts of text. Considering the growing number of textual datasets, this model is a very welcome addition to the NLP toolbox.
- BERT can easily take advantage of pre-trained models and is an enabler of fast results with excellent performance. This method is called Transfer Learning and discussed in my blog on Transfer Learning. The use of Transfer Learning is vital, given one of the challenges in NLP is the shortage of training data.
- BERT allows for fine-tuning by adding a simple layer to the model resulting in a new purpose-specific model. The fine-tuning stage uses the same parameters as BERT training and reduces the complexity of fine-tuning significantly. This technique is commonly used for creating new NLP specific tasks.
BERT pipeline
A BERT pipeline [7] consists of two distinct phases (see Figure 2). The first phase is the pre-training phase, where large amounts of unannotated data (unsupervised) are trained into a model. The second phase is the fine-tuning phase, where the pre-trained model is used as a base (Transfer Learning) added with a small number of layers specific to the NLP task at hand. This further trains the model using the task-specific labeled data, e.g. Q&A, sentence classification or sentiment analysis. Examples of those tasks could be question & answer, sentence classification, or sentiment analysis. The fine-tuning phase is using the same parameters (weights) as the pre-training phase.
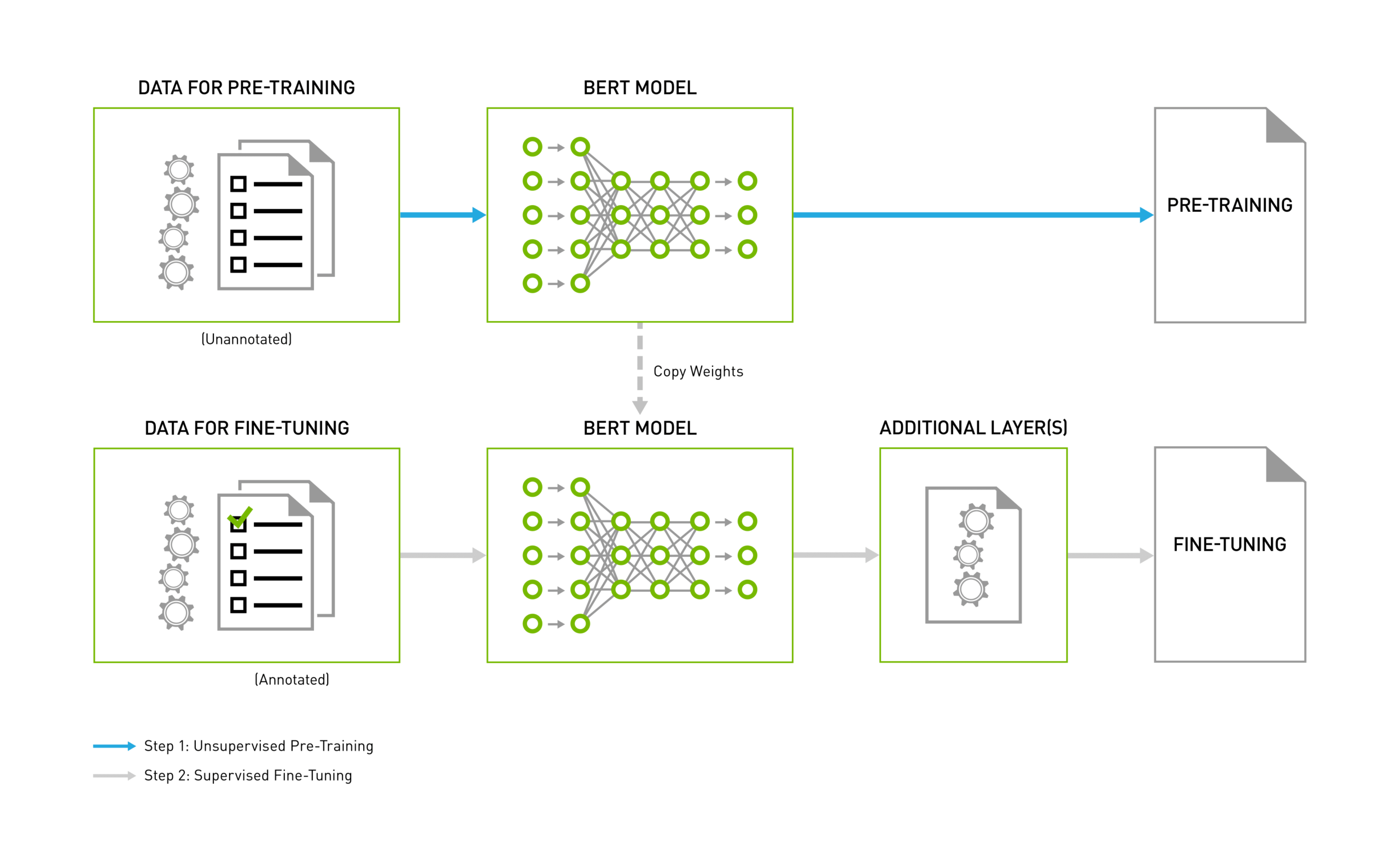
| Figure 2 – BERT pipeline |
BERT Performance
In figure 3 [2] we observe the comparison between Left-to-Right language modeling (in RED) and BERT’s bi-directional masked language modeling (MLM) approach (in BLUE).
The Left-To-Right model converges faster than the bi-directional model. However, it doesn’t take many pre-training steps for the bi-directional approach to catch up and outperform the Left-To-Right method. BERT’s ability to analyze large amounts of data is vital: the more training steps (more data) there are, the higher the potential accuracy of the model.
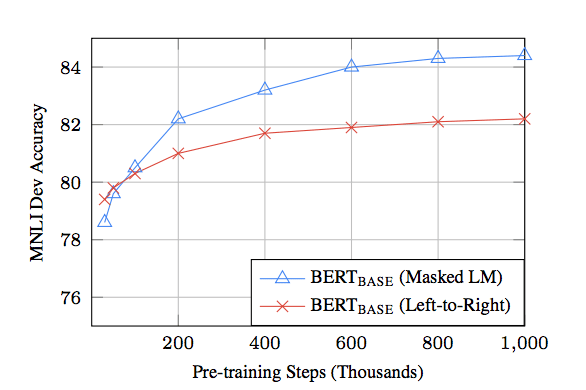
| Figure 3 – Performance Lift-To-Right vs. Bi-directional |
Use case – Google Search
On October 25, 2019, Google announced [3] it is improving Google Search to address complex or conversational queries. The announcement referred explicitly to BERT as the neural-network technology integrated into Google Search to both ranking and featured snippets. People can search in a way that feels more natural. At first, it will be rolled out for U.S. English, followed by more languages and locations over time.
Google provided a few examples to illustrate the new capabilities. In this example (see Figure 4), the user would like to know what the visa requirements are for a Brazilian traveler to visit the USA in 2019. The query could look like this “2019 brazil traveler to usa need a visa”. The word “to” and its relationship to the other words in the query are particularly important. The previous algorithms would not be able to understand the connection and returned results for U.S citizens traveling to Brazil, which is the other way around from what the user meant.
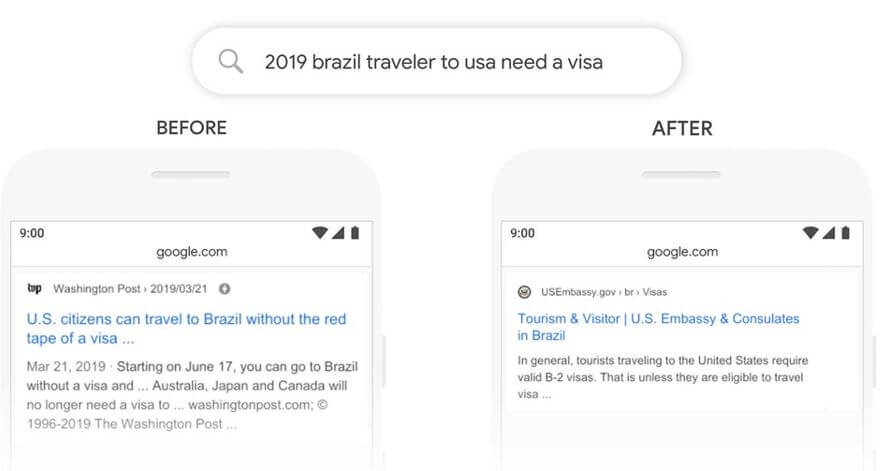
| Figure 4 – Google Search with BERT example |
Google does recognize that BERT isn’t perfect; however, it’s a big step forward towards human understanding in Search. As with any other AI-based technology, we expect further improvements as it learns from past behaviors.
In conclusion
Natural Language Processing (NLP) leverages Artificial Intelligence (AI) to create the ability for a computer to understand, analyze, manipulate, and generate human language. In recent years significant progress has been made in the area of NLP. In October 2018, Google released BERT which uses the context and relations of all the words in a sentence, rather than one-by-one in order. It reveals the full meaning of a word by looking at the words that come before and after it. The bi-directional design is what makes it more useful and different from traditional models. Additionally, it can process large amounts of text and language.
The use of pre-trained models (Transfer Learning) has opened the door to many new NLP initiatives by fine-tuning pre-trained models for specific NLP tasks such as question & answer, sentence classification, or sentiment analysis.
Google announced that they are starting to use BERT in Google Search for a better understanding of queries and content.
BERT can be adapted and expanded with ease. For example, Facebook announced in September 2019 [6] that they have open-sourced “RoBERTa”. It is Facebook’s implementation of Google’s BERT neural-network architecture. They made several improvements to the model’s parameters and trained the network with an order-of-magnitude more data.
References:
[1] Shilakes, Christopher C., Tylman, Julie (November 16, 1998), “Enterprise Information Portals” (PDF). Merrill Lynch
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova (October 11, 2018), “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”
[3] Pandu Nayak, Google (October 25, 2019), “Understanding searches better than ever before”
[4] Google AI Blog (November 2018), “Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing”
[5] Keita Kurita (January 9, 2019), Paper Dissected: “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”
[6] Infoq (September 24, 2019), “Facebook Open-Sources RoBERTa: an Improved Natural Language Processing Model”
[7] NVIDIA (March 18, 2019), “BERT for TensorFlow”