Artificial Intelligence is now one of the most capital-intensive investments enterprises make. Organizations are spending tens or even hundreds of millions of dollars on GPU infrastructure, expecting rapid progress and measurable returns. Yet in practice, many AI clusters operate far below their potential.
The cause is rarely the GPUs themselves. More often, performance and ROI are constrained by a less visible but decisive factor: network bottlenecks in the fabric connecting those GPUs.
When AI infrastructure networks do not support distributed AI workloads, GPU utilization drops, training takes longer, and infrastructure costs increase without delivering proportional value. In such environments, adding more GPUs does not improve outcomes; instead, it worsens inefficiency.
The Economics of Idle GPUs in AI Infrastructure
Modern AI training is inherently distributed. Instead of running as stand-alone accelerators, hundreds or thousands of GPUs work together in tightly coordinated clusters, exchanging gradients and synchronization signals thousands of times during every training run.
However, when the network cannot move this data quickly and predictably, GPUs pause and wait for other nodes to catch up.
Meanwhile, those pauses produce no compute value. As training scales, the delays compound, extend training timelines, reduce effective utilization, and inflate the true cost of AI infrastructure
For organizations investing heavily in AI infrastructure, this has direct financial implications:
- Longer training cycles delay time-to-market for AI products.
- Underutilized GPUs increase the effective cost of compute.
- Scaling inefficiencies require larger clusters than expected.
In practical terms, network bottlenecks can reduce the productivity of a GPU cluster by 30–50% or more.
Why AI Workloads Create Network Bottlenecks
Traditional data center networks are not built for AI. They were designed to support client-server application traffic, storage access, and virtualization. These workloads tolerate modest latency and moderate bandwidth and generate mostly north–south traffic, data moving between users, applications, and databases.
AI clusters demand something quite different. They generate enormous amounts of east–west traffic, meaning data constantly moves between servers within the cluster itself.
The result is a workload pattern that stresses networks in ways most enterprise infrastructure was never designed to manage. AI networks require:
- Ultra-low latency communication.
- Extremely high throughput.
- Predictable network performance.
- Lossless transport for distributed training.
Without specialized networking architectures, such as high-bandwidth fabrics designed for distributed computing, AI clusters frequently encounter bottlenecks.
Key AI Networking Concepts
These concepts explain why AI clusters often fail to scale as expected. Each represents a point at which network bottlenecks directly determine GPU utilization, training speed, and overall return on investment in infrastructure.
| Term | What it means | Why it matters |
|---|---|---|
| Gradient | The data generated by each GPU during training is used to update the model. | Must be shared across GPUs continuously; delays directly reduce GPU utilization. |
| Synchronization | The process of combining gradients from multiple GPUs across the entire cluster ensures all replicas of the model remain consistent. | Requires high-speed communication between nodes. Synchronization latency turns network delays into idle compute time. |
| AllReduce | A communication method used to aggregate data from all GPUs and distribute a final, consistent result back to every GPU. | An intense network operation during AI training. Performance collapses if the fabric cannot keep up. |
| Barrier | A synchronization point where all GPUs must wait until every node completes its task. | Network bottlenecks cause the entire cluster to stall. A single slow node or path stalls the entire cluster. |
| East-west Traffic | Data movement between servers within the cluster. | AI workloads generate massive east–west traffic. This stresses networks not designed for many to many communication. |
GPU utilization is not a tuning metric. It is the visible output of whether the network can sustain collective communication at GPU speed.
The GPU Synchronization Problem
The most common network bottleneck occurs during model synchronization. At regular intervals during training, every GPU must share its computed updates with the rest of the cluster. The system then aggregates those updates and distributes the result back to every node.
Training will not continue until this synchronization is complete. If even one GPU finishes late, or if the network cannot deliver updates quickly enough (especially between cluster nodes), the entire cluster must wait.
This phenomenon is often described as “the slowest component determines the speed of the cluster”. In this case, the slowest component is frequently the network path between the nodes.
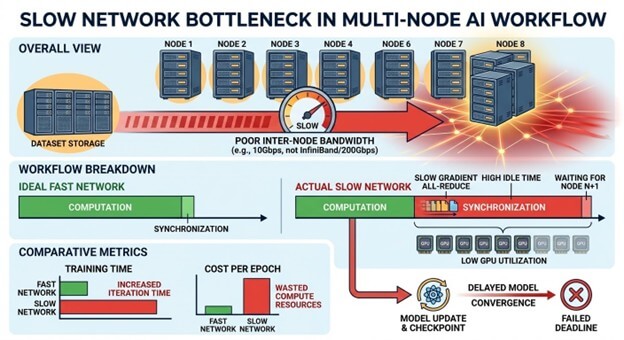
When networking is slow or congested, synchronization stalls the timeline, leaving expensive GPUs idle. These stalls are not tuning issues. They emerge when networks designed for best‑effort, north–south traffic are asked to support sustained, many‑to‑many, east-west communication at GPU speed. Two separate network fabrics are required: one to manage north-south traffic and a second, high-bandwidth, low-latency network to oversee east-west traffic.
The Strategic Implications for Enterprise Leaders
For executives overseeing AI initiatives, networking is no longer a background concern. It is a core determinant of AI productivity and ROI.
Three strategic lessons are emerging across the industry:
1. GPUs Alone Do Not Define AI Performance
Organizations often focus on GPU counts when planning AI capacity. However, the network fabric ultimately determines how effectively those GPUs work together.
2. Infrastructure Architecture Matters More Than Raw Hardware
High-performance AI environments require carefully designed systems that integrate compute, networking, and storage into a cohesive architecture.
3. AI ROI Depends on Infrastructure Efficiency
The success of AI programs increasingly depends on how efficiently organizations utilize their infrastructure investments.
Clusters that run at high utilization complete training faster, reduce compute costs, and accelerate innovation cycles.
The Bottom Line
Artificial intelligence is rapidly becoming one of the most important technology investments organizations make. But maximizing the value of that investment requires looking beyond GPUs alone.
The network fabric connecting those GPUs often determines whether an AI system operates at peak performance or whether it spends significant time waiting.
For executive leaders, the message is clear. AI outcomes depend on infrastructure alignment, not just GPU investment.
If your organization is scaling AI and wants to ensure network bottlenecks are not the limiting factor, HighFens offers an AI networking checkup focused on utilization, scalability, and ROI.
Reach out to sales@highfens.com to start the conversation.