HPE’s presentation at AI Field Day 8 in May 2026 made a case that is easy to agree with: the right AI infrastructure is the one that matches where you are today, not where a vendor’s roadmap wants you to be. Not every enterprise chasing AI is chasing the same thing.
A hospital piloting a diagnostic assistant has different infrastructure requirements than a financial institution running real-time fraud detection at scale.
A retailer deploying loss-prevention AI at the edge needs something completely different from a Hyperscaler training a 70-billion-parameter model.
Why AI Infrastructure Requirements Are Not Uniform
Industry AI Use Cases Drive Different Infrastructure Needs
AI use cases differ in important ways.
For example, healthcare AI requires strong data sovereignty and compliance. Meanwhile, manufacturing AI relies on real-time edge inferencing with limited connectivity. In financial services, AI supports high-throughput processing under strict security controls. By contrast, media and entertainment teams run GPU-heavy workloads and can accept more latency.
As a result, each industry starts from a different point and scales at a different pace.
AI Maturity Stages Change Infrastructure Requirements
Moreover, infrastructure needs change as organizations mature. According to Sema4.ai’s 2026 AI maturity research, AI adoption follows a clear path. It moves from ad hoc experimentation to embedded, autonomous AI. Therefore, each stage requires a different technology foundation.
Likewise, a proof of concept rarely scales to production across thousands of endpoints. Gartner predicts that 40% of enterprise applications will include task-specific AI agents by the end of 2026. That figure was under 5% in 2025. As a result, infrastructure needs will look very different in the next two years.

The implication is simple. A vendor that serves only one maturity stage can leave customers stranded as they grow. Yet many organizations still fall into that trap. Instead, they let a vendor roadmap drive the decision rather than their business needs.
How HPE Maps Its Portfolio to the AI Maturity Curve
HPE Aligns AI Infrastructure to Enterprise Readiness
At AI Field Day 8, Bharath Venkat, Senior Principal Product Manager at HPE, presented a clear continuum. HPE maps each solution to an organization’s current AI maturity stage. In other words, the portfolio supports today’s needs, not an aspirational future state.
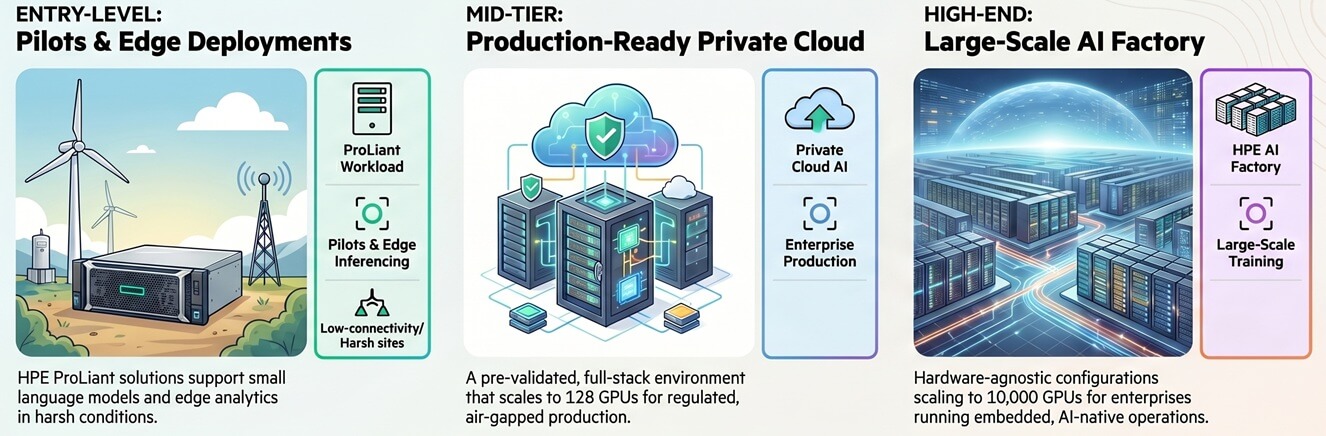
Entry-Level AI Infrastructure for Pilots and Edge Deployments
At the entry point, HPE ProLiant workload solutions target small pilot deployments and edge inferencing. For example, the recently released HPE ProLiant DL145 Gen11 and EL2000 chassis are well-suited to sites with limited connectivity. They also support harsh conditions, including altitude and temperature extremes.
As a result, teams can run small language models, vector databases, and edge analytics closer to where data is created.
Production-Ready Private Cloud AI for Enterprise Deployment
For organizations moving from experimentation to production, HPE Private Cloud AI offers a pre-validated full-stack environment. It removes much of the complexity of building an AI-ready data center. In addition, it includes HPE Morpheus for VM management, AI Essentials software, and NVIDIA Blueprints. HPE configures and validates those components together.
As of 2026, Private Cloud AI scales to 128 GPUs. It also supports air-gapped deployments for regulated industries with strict privacy requirements. Moreover, IDC named HPE a Leader in its MarketScape for worldwide private AI infrastructure systems. IDC cited HPE’s ability to simplify integration between data pipelines and AI workloads.
AI Factory Infrastructure for Large-Scale Enterprise Operations
At the high end, HPE AI Factory supports large-scale training and processing. It offers hardware-agnostic configurations that scale to 10,000 GPUs. Therefore, it fits organizations that have moved beyond pilots and into AI-native operations. Larridin’s research says 28% of enterprises have embedded AI across multiple business functions.
Moreover, HPE ties that scale to a broader infrastructure strategy. As Antonio Neri, HPE President and CEO, said at NVIDIA GTC 2026, “AI is only as good as the infrastructure and data behind it.” He added that organizations need the right data, intelligence, and vision to capture the AI opportunity.
Why AI Infrastructure Planning Does Not End at Purchase
Infrastructure Strategy Must Support Long-Term AI Growth
Venkat’s presentation reinforced a point many infrastructure teams miss. AI infrastructure is not a one-time purchase. Instead, it requires planning for growth, change, and operational maturity.
Research from Dialectica clearly shows the risk. Organizations that skip maturity often try to run production workloads on pilot-grade infrastructure. As a result, they rebuild their foundations as they try to scale. That misalignment creates avoidable cost and delay.
HPE addresses this problem with a portfolio built for non-disruptive scaling. It protects GPU investments across generations. In addition, HPE Compute Ops Management provides unified management. Modular form factors also help infrastructure adapt as workloads grow.
For example, a financial services firm and a regional manufacturer may start with the same pilot platform. However, they will scale in different ways and at different speeds. HPE organizes its portfolio as a continuum rather than a simple product line. Therefore, it can support both paths over time.
Frequently Asked Questions
Overall, AI infrastructure should reflect where an organization is on its AI journey. A pilot environment may work for experimentation, but it often cannot support production-scale requirements. When infrastructure and maturity are misaligned, organizations usually face higher costs, delays, and unnecessary rework as they scale.
HPE ProLiant workload solutions, including the DL145 Gen11 and EL2000 chassis, are a good fit for organizations starting with AI. They support edge inferencing, small language models, and vector databases, especially in environments with limited connectivity or harsher operating conditions.
HPE Private Cloud AI is a pre-validated full-stack platform for organizations moving from AI experimentation into production. It combines HPE compute, NVIDIA GPUs, HPE Morpheus, and NVIDIA Blueprints into a single integrated environment. In addition, it scales up to 128 GPUs and supports air-gapped deployments for regulated industries.
HPE AI Factory is designed for large-scale AI training and inference. It supports hardware-agnostic configurations that scale to 10,000 GPUs. Therefore, making it a strong option for enterprises running AI across multiple business functions.