This article originally was published on LinkedIn by our CTO on June 13th, 2018. The article has been updated and re-posted here.
HPC
High-Performance Computing (HPC) became popular in the ‘60s with governments and academics. They required to solve large computational problems and could afford to take advantage of the advancements in computer technology. Until then most of the complex problems were solved manually by people, a slow process and error-prone. The HPC systems could solve those problems a lot faster and more accurately. But, the technology itself was very expensive to acquire and maintain. On top of that, a lot of time was spent writing programs and uploading them to the system. Consequently, this was limiting the number of available applications and keeping changes to a strict minimum. All that combined meant that HPC was a niche market and only available to the people who could afford and justify the cost.
Big Data
Around 2011, “Big Data” started gaining market share mostly driven by the opensource community (Hadoop). The availability of affordable infrastructure hardware (compute, network and storage) from a variety of vendors. This gave people access the power of problem-solving in a cost-effective way.
It didn’t take long for the HPC community to realize the benefits of “Big Data”. Some of the methodologies were introduced into HPC designs allowing for a more efficient sharing of resources between HPC and Big Data. With the introduction of “Big Data” the emphasis shifted from workloads being computational centric to a more data-centric approach.
Around 2015, the convergence of HPC and Big Data was well underway and maturing in the market space. The availability of large quantities of data in a variety of market segments and the ability to ingest and store that data has created an even greater need for massively parallel computing to process that data in a reasonable amount of time. In some cases that must happen in real-time. It isn’t just an infrastructure problem but also a need for new software methodologies and tools that can scale with the growing amount of data. We have truly entered the data-centric world.
AI
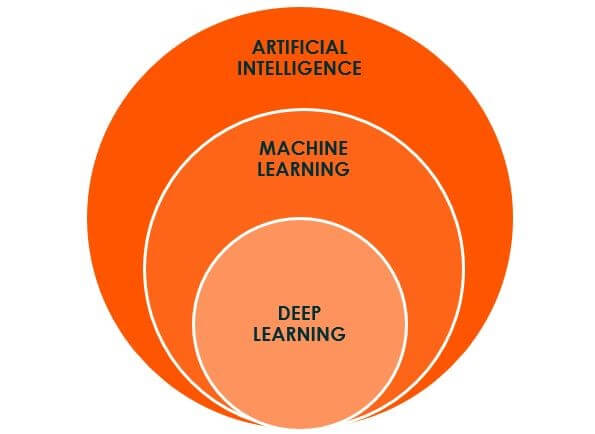
This is where Artificial Intelligence (AI) comes into play. Consequently, bound to disrupt the digital world with a new wave of innovations. AI is a term that is usually used to describe when a machine mimics cognitive functions that humans associate with other human minds including learning and problem-solving. The goal is to obtain an algorithm (classification) by analyzing data that can be used to predict future behaviors or output. The algorithm is improved by a continuous process that feeds it new data.
AI-Machine Learning
Machine Learning (ML) is a subfield of AI and a methodology that handles the “classification” process automatically. However, it does require significant help from humans to describe and extract the “features” of the problem to be solved. What are “features”? Imagine you want to use AI to find out which pictures contain a cat or a dog. The “features” are what defines a cat or a dog. With the “features” defined, the “classification” process can start. The adoption rate of ML is relatively high and matured enough. As such, the barrier to enter and apply ML doesn’t require a Ph.D. anymore.
AI-Deep Learning
What would it take to have the feature extraction done automatically? That is exactly one of the things Deep Learning (DL) is trying to achieve. DL is a subfield of ML.
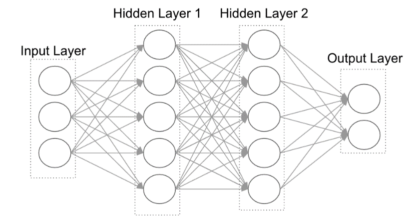
If we have a large enough dataset then we can use a process to extract the “features” automatically. How much more data (vs. ML)? Well, it depends on the problem to be solved and its complexity but let’s define it as significantly more data. More data also means higher processing needs. For this, DL is relying on Deep Neural Networks and consists of one or more hidden and independent neural layers which process the data like the way the human brain works.
DL has a lot of data to process and due to the complexity of the neural networks, it requires massive parallel processing. The use of “accelerator cards” such as GPUs (NVIDIA) and Tensor (TPU, Tensor Processing Unit from Google) assist the CPUs with the processing. The opensource community has been delivering software frameworks at a steady rate. They provide integration of the accelerator cards with existing infrastructure as well as tuned math and statistical libraries as an all in one bundle. A single framework can’t solve all problems equally well and as such many frameworks are available to address specific domain problems. DL can deliver better results than ML and with a lower error rate. We haven’t seen many DL deployments yet but is clearly the future and many enterprises have started experimenting with DL.
Do I need AI?
In conclusion, do I need AI? Enterprises that have introduced AI in their workflow have seen economic benefits such as increased revenue, cost reduction, and improved asset utilization. AI is impacting all industries and no industry will stay unaffected by the advancements in AI.