With GPUs’ increasing capabilities, we can now explore more complex models. Companies like NVIDIA continuously deliver innovation, with new GPU hardware released every two years. These GPUs are crucial for accelerating AI workloads.
Many organizations utilize GPU clusters to achieve their AI goals. Beyond the need for more complex models, time to market also plays a significant role in decision-making regarding acquiring AI infrastructure.
The AI consumer market demands that models be released and updated at an ever-faster pace. Organizations that can meet these expectations have a competitive edge.
Building AI models, however, requires substantial infrastructure, the ability to keep up with innovations, and the capacity to meet market expectations.
The old saying, “Let’s throw more hardware at the problem,” is no longer feasible. Budgets are limited, and the associated data center requirements, such as power and cooling, will increase operational expenses (OPEX).
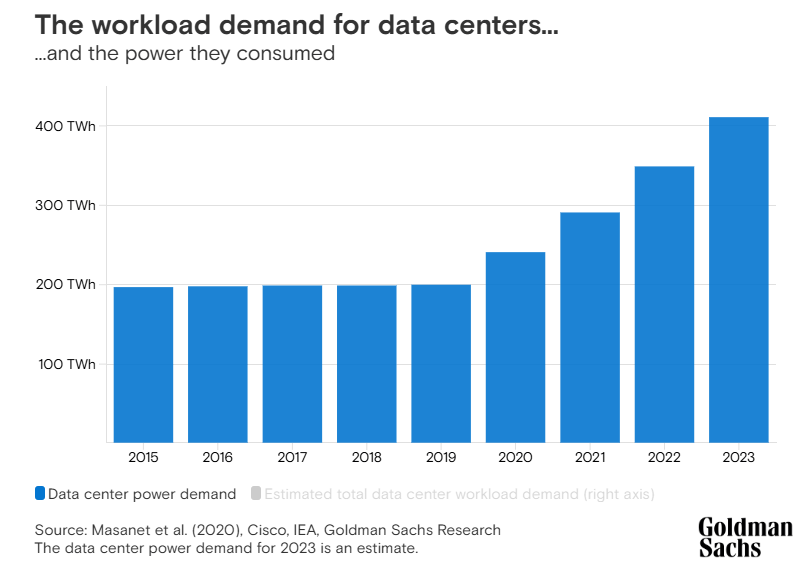
GPUs require a significant amount of power, and growing energy needs are a primary concern.
According to Goldman Sachs, data centers are responsible for 3% of the total US power usage and are expected to grow to 8% in 2030.
GPU (in)efficiency
It is time to examine the efficiency of AI Clusters more closely. The efficiency of GPUs is crucial to improving the overall efficiency of AI Clusters.
You can only improve what you measure. The initial step is to measure and then improve based on the findings.
GPU efficiency is a hot topic, and at AI Tech Field Day, VMware by Broadcom and MemVerge both presented on the topic.
MemVerge
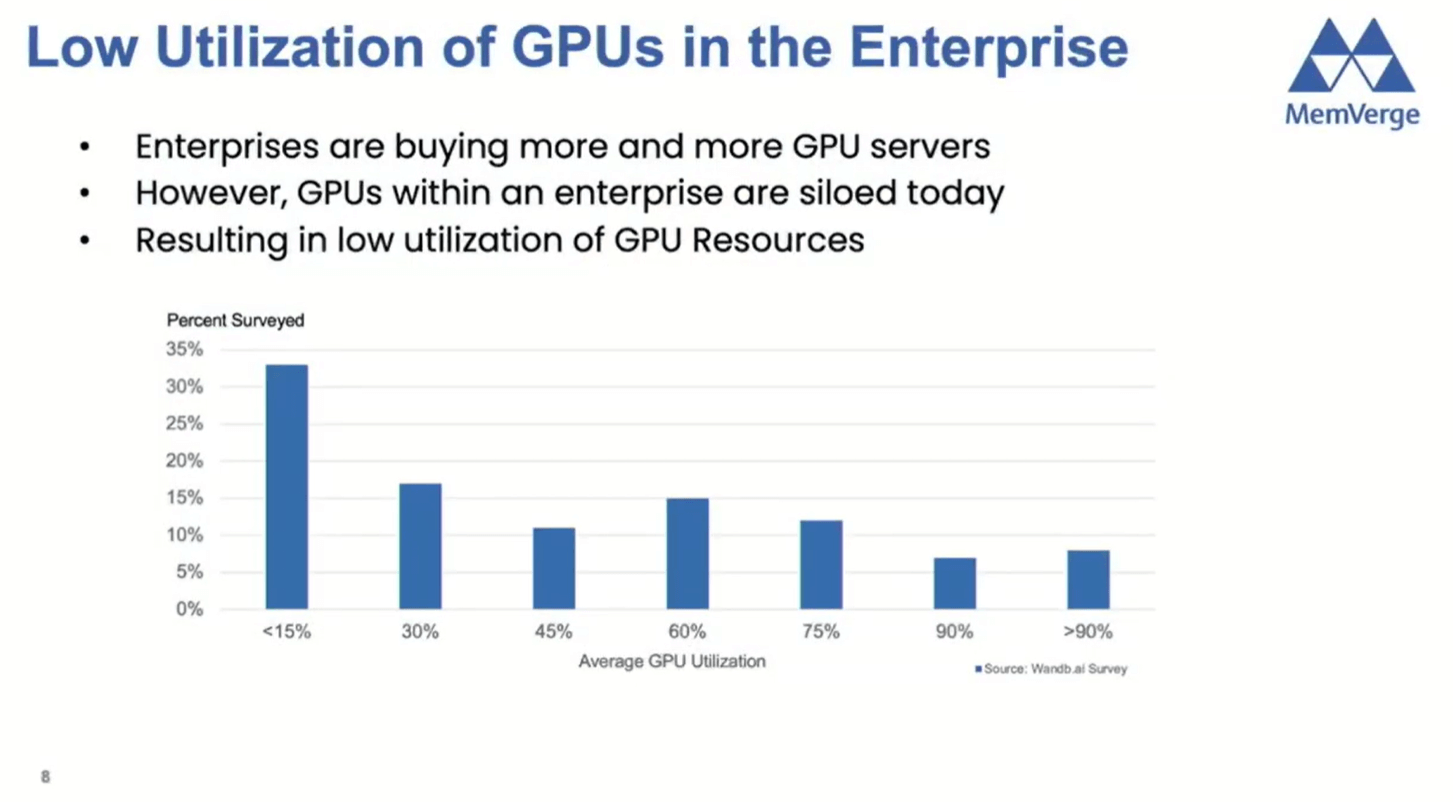
In their presentation, MemVerge provided observations regarding GPU utilization. The surveyed organizations have hundreds to thousands of GPUs, and one main reason for the low utilization is that different groups own the GPUs and end up siloed.
The X-axis shows the average GPU utilization, and the Y-axis shows the percentage of people in the survey who matched that utilization. The survey was done by Weights & Biases.
Roughly one-third of the surveyed had less than 15% utilization, and less than 10% of the surveyed had over 90% utilization. There is plenty of room for improvement.
MemVerge’s “Memory Machine Al” allows organizations to dynamically schedule jobs based on priority, workload type, and available resources. This approach ensures maximum throughput across your entire cluster.
The features of the Machine are:
- Strategic Resource Allocation
- Ensure critical projects get the GPI-Js they need, reduce idle time
- Flexible GPU Sharing
- Dynamically allocate idle GPI-Js to other projects, then revert as needed
- Real-Time Observability & Optimization
- Monitor GPI-J usage and adjust workloads on the fly
- Priority Management
- Intelligent scheduling balances project deadlines and resource demands
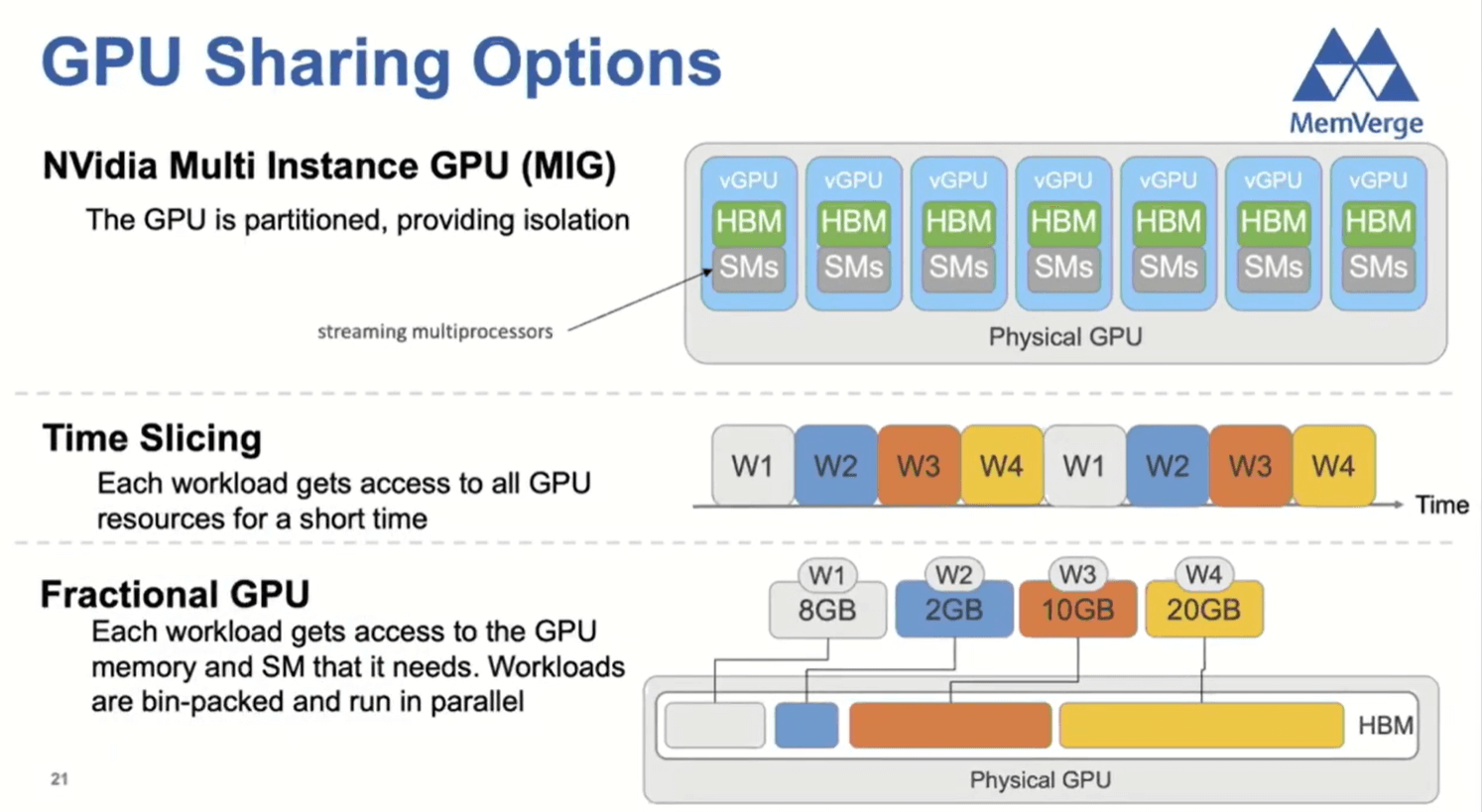
MemVerge also shared options on what can be done to efficiently share GPUs as shown in the diagram below..
VMware by Broadcom
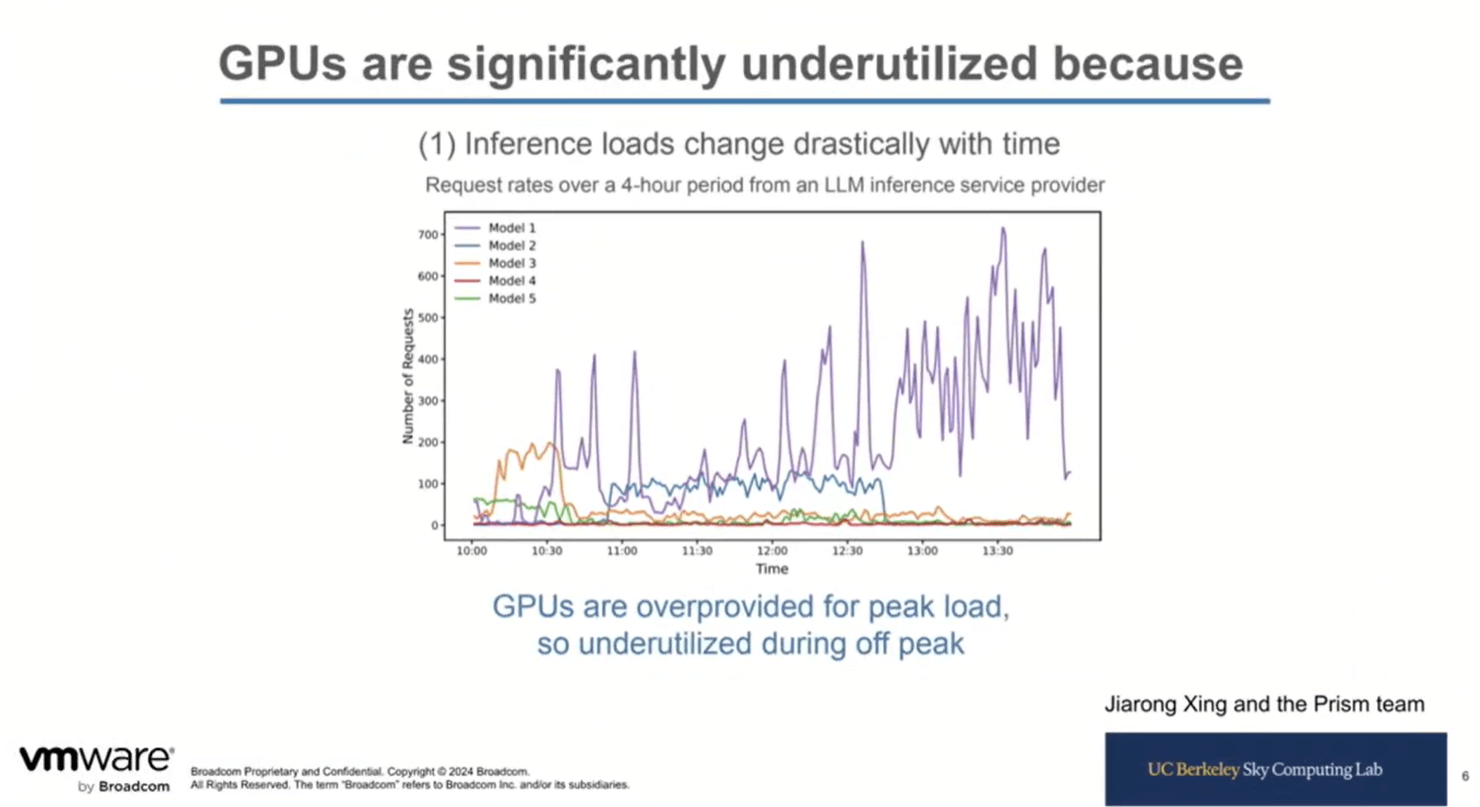
Today’s deployment practice involves allocating GPUs per model, which results in significant underutilization because of inference workload patterns.
The graph below shows five different inference workload models and their utilization.
Some models are used more than others, but even the busiest models are unevenly utilized.
The problem is accentuated by GPU Hoarding, in which teams are not willing to share resources such as GPUs, adding to the inefficiency.
The VMware Private AI platform allows teams to bring in their GPUs under the platform’s management. They will have first-priority access to the GPUs and be used by lower-priority workloads when not requested. The lower priority request can be made by the same team or another team, maximizing the utilization across all GPUs.
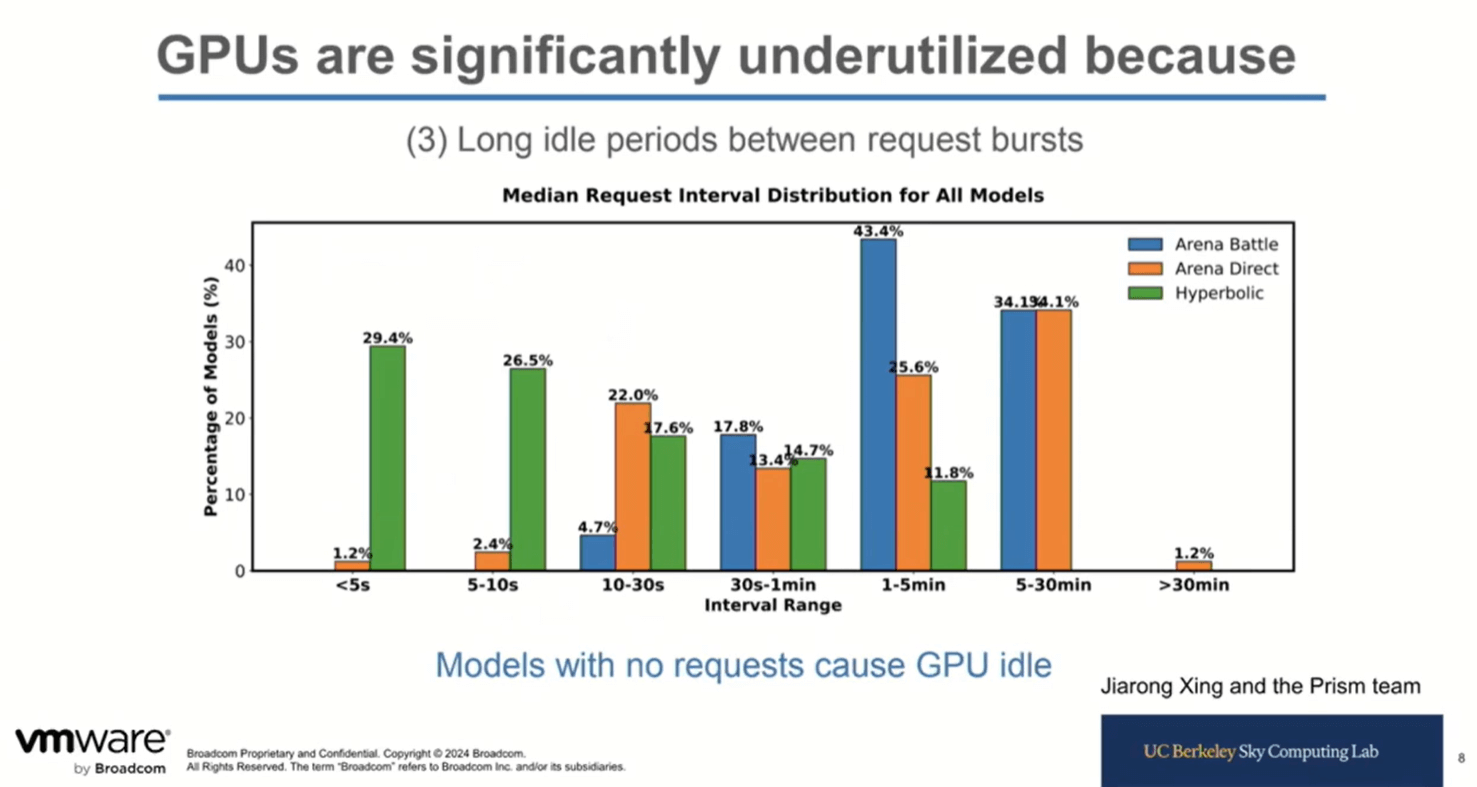
Another contributor to GPU inefficiency is the idle time between request bursts. The graph shows that the idle time can range from a few seconds to over thirty minutes.
Conclusion
There are many ways to accelerate AI workloads efficiently. GPUs are in high demand, but they come at a price, and a significantly improved version is released every two years.
Powerful tools like MemVerge and Broadcom can improve GPU efficiency and work across the various GPU generations.
The need for efficiency hasn’t gone unnoticed with GPU vendors such as NVIDIA. Their market research indicates that using tools can, in some cases, significantly improve efficiency.
According to NVIDIA – “Our customers see improvements in utilization from around 25% when we start working with them to over 75%.”
Essential features to look for in an efficiency tool (not limited to):
- Dynamic resource allocation
- Fair-share scheduling
- Ability to integrate the tool in the customer development/deployment framework
- Support for NVIDIA Multi-Instance GPU (aka MIG)
In return, you can expect Improved productivity and cost efficiency.
Please check out the Tech Field Day’s AI Field Day 6 page for the complete presentations.