The Artificial Intelligence (AI) solution that we recently deployed at Cerence was designed based on our many years of experience building sizeable High-Performance Computing (HPC) clusters for AI. We proposed a data-centric architecture that heavily relies on an innovative storage solution from Weka. The customer was looking for a hybrid solution that would allow them to run on-premises and also take advantage of the public cloud for peak capacity and future growth. As such, the overall design is capable of running workloads on-premises or in a public cloud-based on customer-driven policies.
Virtual assistants in the Automotive world
Cerence builds AI models for major automobile manufacturers worldwide. Its automotive cognitive assistance solutions power natural and intuitive interactions between automobiles, drivers and passengers, and the broader digital world. Cerence produces one of the world’s most popular software platforms for building virtual automotive assistants — fueling AI for a world in motion. AI is used to deliver an exceptional in-car experience based on a deep understanding of language, culture, and human behavior.
![]()
![]()
Cerence turned to HighFens for expertise on the project to deliver a new AI cluster that would empower R&D to achieve its research goals. Cerence R&D mostly builds speech-language models for Natural Language Processing (NLP) and Natural Language Understanding (NLU).
A growing number of Cerence’s workflows rely on Deep Learning (DL) frameworks paired with NVIDIA® GPUs to obtain faster and more accurate results. The ability to stage data closer to the GPU is crucial for achieving high performance.
Besides, Cerence had a requirement to make the data to be processed available through a POSIX interface. It would provide consistency and compatibility with existing tools and applications.
The new AI cluster’s end-to-end design replaces the previous decade-old architecture that was also designed by the HighFens team.
Data-centric architecture
Data
The customer has many petabytes of data but processes only a fraction of that data at any one point in time. It did not make sense to store all their data on high-performing, expensive storage.
For that reason, we opted to take advantage of Weka’s tiering capabilities:
- Front-end storage:
- Use high-performing, low-latency NVMe drives to provide just the storage capacity needed to store the data that will soon be processed.
- The storage capacity can accommodate only about 25% of the entire data footprint, but this can vary from customer to customer.
- Back-end storage:
- The bulk of the data (75%) is stored in cost-effective object storage.
The data is always accessible through a POSIX interface but can reside in back-end storage until it is needed for processing. WekaFSTM, the Weka file system, dynamically and transparently moves the data between the front and back ends depending on usage patterns.
It is important to note that the front and back ends can scale independently. For example, the back-end storage can be sized to accommodate additional data collection. Conversely, if more processing resources are being added, then add more capacity to the front-end storage.
Modular design
Data from many sources are generated in large volumes at an increasing pace. Therefore, having an AI architecture that can scale and grow with the business is essential. We frequently see architectures that look fine at first but cannot scale and will cause various bottlenecks, including network congestions that prevent the compute resources from accessing data in a timely fashion. Typically, this results in decreased overall performance, higher data access latency, longer wait times, or even failed jobs.

Furthermore, the architecture must deliver a cost-effective solution with a predictable price tag that meets budget constraints.
We proposed an architecture with a “modular” design that scales linearly by incorporating additional building blocks to accommodate any growth. As more computation power is added, the need for IO bandwidth also increases. Each module consists of a server that contributes both computing power and front-end storage bandwidth. The complete set of modules provides the total capacity of the AI cluster.
Module
A module consists of a 1U server (HPE DL360 Gen10) that contributes compute, storage, and networking resources to the overall solution. Each server comes with 40 physical cores, 512GB RAM, 2x25Gb/sec Ethernet ports, 2×3.2TB NVMe drives, m.2 drives for the operating system and local storage, and 1 x NVIDIA® T4 GPUs.
Figure 1 shows the logical architecture built around the WekaFS file system. Each of the 40 modules comes with the Weka client and allows for horizontal scaling.
All the modules together make up the front-end storage (256TB of NVMe). The S3 Ceph data lake represents the Weka back-end.
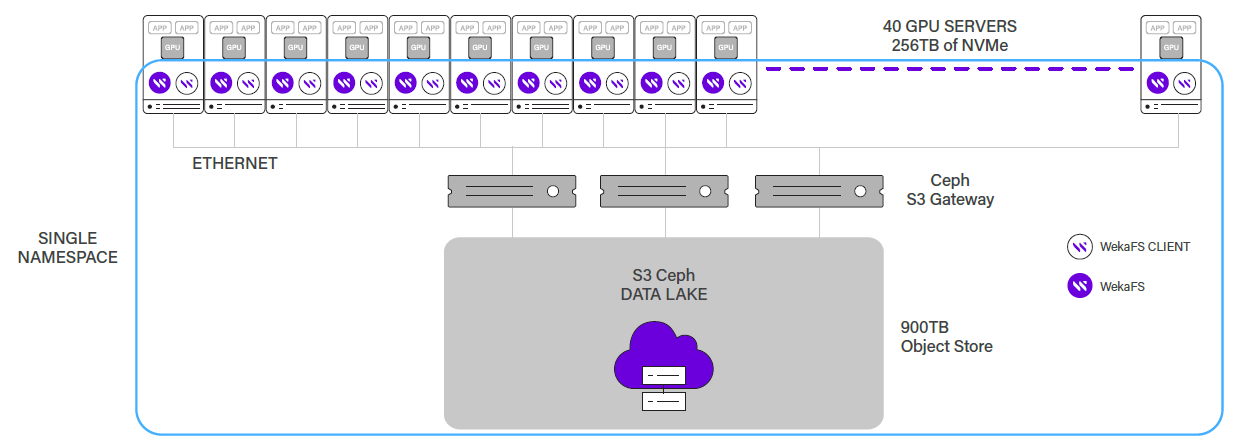
WekaFS Services:
- A set number of physical cores and some RAM capacity are dedicated per server to WekaFS services.
- FAQ: “Why allocate cores? Isn’t that a waste?” Answer: a high-performance file system service needs CPU cycles regardless of whether or not those resources are dedicated. However, without dedicated cores, you could end up in a situation where both jobs and the file system services are competing for the same cores — resulting in unpredictable performance and sluggish file system performance.
Storage:
- The 2 x 3.2TB NVMe drives are exclusively for the Weka file system and contribute to the overall front-end storage capacity.
- The running jobs have local access to the drives and benefit from very high performance and low latency.
- The WekaFS automatic tiering capability will take care of moving data to and from the NVMe drives when needed.
Network:
- There are two network ports, one of which is dedicated to WekaFS services to prevent non-Weka traffic from causing bottlenecks and impacting performance.
Compute:
- Many of the workloads require the same data to be accessed by both CPUs and GPUs. Rather than having separate CPU and GPU servers and moving the data around, we added an NVIDIA® T4 GPU to each CPU server.
- With the data already on the Weka front-end storage, some GPU-based workloads now run three times faster than when moving data between separate CPU and GPU servers.
- Although the NVIDIA® T4 is labeled as an Inference card, it is beneficial for smaller GPU workloads. Its form factor and low power, when combined with Weka, make it a perfect match for our modular design.
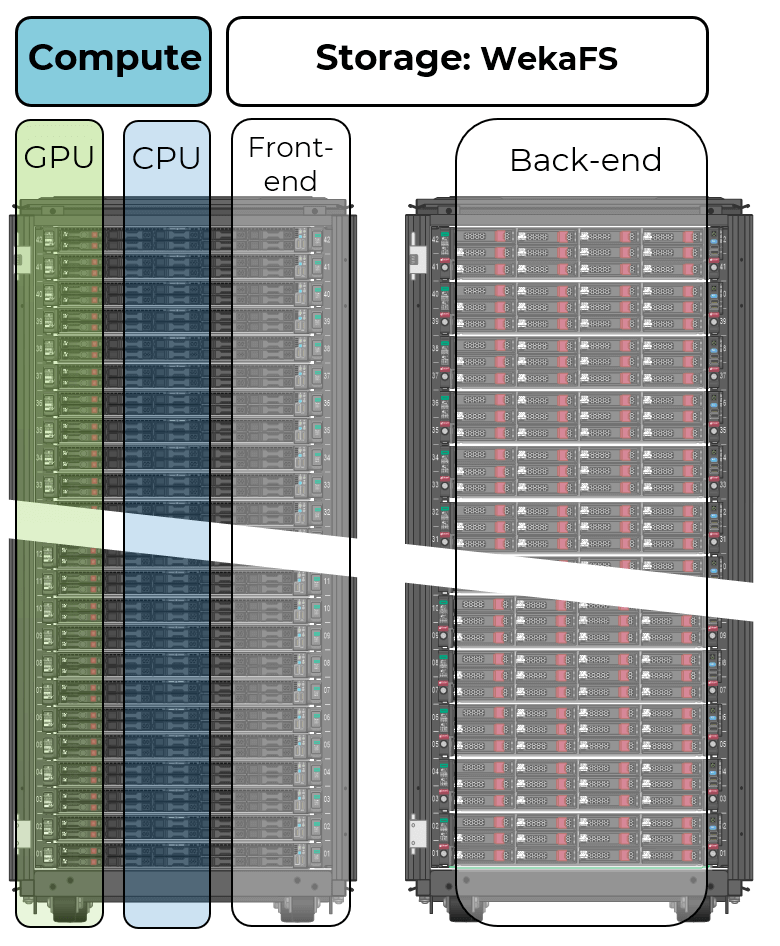
Figure 2 represents the physical layout: on the left, a rack of HPE DL360 Gen 10 servers, and to the right a rack with HPE Apollo 4200 Gen 10 severs. The compute portion is shown as the CPUs augmented with the NVIDIA® T4 GPUs. Compute and storage racks can be added to accommodate demand.
Solution benefits
The Weka platform provides data access through a single namespace and a POSIX file system interface.
Using Weka in a tiered fashion, we were able to provide the equivalent IO performance and capacity of a much larger system but with a smaller footprint.
Embedding the WekaFS services into the compute nodes provides additional savings in server/network hardware and allows performance to be scaled horizontally. After working with other high-performance file systems such as IBM Spectrum Scale and Lustre, we found the Weka solution to be much easier to install and maintain.
The snapshot capabilities make data movement between on-premises and the public cloud a breeze — making snapshots a crucial feature of the hybrid architecture and critical for Disaster Recovery and archiving.
WekaFS also allows for easy patching, and installing an update is entirely non-disruptive for the cluster. Also, WekaFS has built-in monitoring with phone-home capabilities. The Weka Technical Support Team will proactively reach out if it detects a problem or unusual behavior.
Weka is hardware-agnostic, and hence there is no lock-in to specific hardware, which opens the door for easy upgrade of drives or integration of newer drives as they are released in the market.
![]()
![]()
To read Weka’s case study on Cerence, click here. For more information about Weka and AI, see the WekaFS: The Weka File System and WekaFS™for Weka AI™ datasheets.
HighFens, Inc. provides consultancy and services for end-to-end scalable HPC/AI solutions. Our customers look for innovative solutions that are reliable, scalable, and cost-effective. The HighFens team has more than 20 years of experience in HPC, Big Data, and AI, with a focus on data management and highly-scalable solutions Feel free to reach out if you are looking for help with a project or have any questions. For more information, please visit our website and our blog page for the latest updates.